
Estrategias de migración
La arquitectura fluida, parte 2

En la parte anterior vimos cómo la arquitectura perfecta no existe; nuestra única esperanza es poder migrar rápidamente de una a otra para responder a los cambios a los que nos enfrentamos.
Llegamos ahora a al catálogo de estrategias. Vamos a describir varias técnicas que se pueden usar para realizar una migración, de las más bruscas a las que son completamente reversibles.
¿Quieres decir “patrones”?
Tras el gran éxito del libro de Gamma et al, Design Patterns, la palabra “patrón” se usa a menudo (y se abusa de ella aún más a menudo) el diseño de sistemas. Los patrones vienen a ser piezas que tienen su rango de aplicación muy concreto según la situación.
No es así en nuestro caso. Ante una migración podemos usar varias de las técnicas que vamos a describir. Podemos elegir una u otra según lo fluida que queramos que sea la migración, no la funcionalidad que queremos conseguir (que es siempre la misma). De ahí que prefiramos el término “estrategia”, que además no está tan viciado por el uso.
Probadas en combate
Todas las estrategias que vamos a describir están probadas en combate. Intentaremos ilustrar cada estrategia con un caso práctico, aunque curiosamente no es fácil encontrar publicaciones sobre migraciones. Por ello para la mayoría de ellas tendremos que recurrir a ejemplos internos de MediaSmart Mobile.
Aunque la mayoría de los ejemplos son de migraciones de bases de datos, las estrategias pueden usarse igualmente para cualquier migración, sea de código, de datos o de infraestructura. Las bases de datos son un ejemplo prototípico de arquitectura cliente/servidor, así que nos dan un marco de referencia bastante sólido sobre el que analizar cada estrategia.
La lista no es exhaustiva: seguramente el lector pueda imaginar algunas estrategias adicionales y perfectamente útiles. Puedes compartirlas al final del artículo.
Ilustraremos las estrategias relevantes con ejemplos de código de Node.js, la plataforma que usamos en MediaSmart Mobile. Es fácil de transcibir a Java, PHP o a cualquier otro lenguaje porque el código es todo muy sencillo.
Catálogo de estrategias de servidor
En esta primera categoría tenemos estrategias que se implementan puramente en el servidor, sin tener que modificar el cliente salvo para reconfigurarlo.
Parar y arrancar
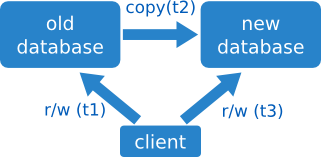
Ésta es la migración de toda la vida:
- se para el sistema,
- se copia la base de datos antigua a la nueva (copia en frío),
- se reconfiguran los clientes para que apunten a la nueva,
- y se vuelve a arrancar el sistema.
Simple, ¿no?
Reversible: no
Esta estrategia requiere dejar de dar servicio, con lo que no es apropiada para situaciones de alta disponibilidad.
La vuelta atrás consiste en volver a parar el sistema, copiar la copia a la inversa, reconfigurar y arrancar.
Claramente no es realmente reversible, y además es un poco chapucera. ¿Os imagináis la fiabilidad que le da a un usuario encontrarse una web caída?
Código de ejemplo
El código de servidor es muy sencillo. Primero tenemos un fichero
settings.js que almacena la configuración:
module.exports = {
redisAddress: 'redis.mydomain.com',
};El fichero intermedio db.js define las bases de datos
que usaremos, en este caso current:
var settings = require('./settings.js');
module.exports = {
current: new RedisAdapter(settings.redisAddress),
};Finalmente, en cada sitio donde usemos la base de datos accederemos
adb.current:
var db = require('./db.js');
db.current.get(key, function(error, result) {
...
});Para cambiar el acceso, sólo tenemos que parar, migrar, cambiar
settings.js y arrancar de nuevo.
Caso práctico: VPC en MediaSmart Mobile
El primer caso práctico que vamos a ver no es precisamente una migración de base de datos. En MediaSmart Mobile necesitábamos migrar nuestra infraestructura en la nube de Amazon (AWS), de una conexión no segura a la VPC (Virtual Private Cloud).
El 3 de marzo de 2015 realizamos la migración: primero creamos una réplica de todos los servidores en la VPC. A continuación paramos los servidores originales, y copiamos los datos a la VPC. Luego arrancamos los nuevos sevidores, y apuntamos el servidor DNS hacia ellos. Tras algunas horas de downtime estábamos arriba otra vez.
El día 5 de marzo nos reportaron problemas en producción, por lo que tuvimos que deshacer la migración. Por fortuna habíamos mantenido las instancias antiguas, así que fue cuestión de parar, volver a copiar los datos y arrancar otra vez. Por ironías de la vida, el problema no se resolvió con esta migración inversa, por lo que dedujimos que tenía otra causa. Curiosamente, una vez que nos quitamos de enmedio la causa más obvia (la migración), el problema real se hizo evidente de inmediato: un fallo que no tenía nada que ver, sino que venía causado por un despliegue anterior.
El día 11 de marzo probamos de nuevo con la misma técnica, y de nuevo tras varias horas de downtime la migración estaba hecha. Como operamos en dos regiones de AWS, todavía teníamos que migrar la segunda región, cosa que hicimos el día 13 de marzo (viernes). Porque total, viernes 13: ¿qué podía salir mal? Y no somos supersticiosos.
La moraleja es algo poco intuitivo: el mayor problema de hacer una migración es muchas veces que nos impide pensar claramente sobre los fallos del sistema, ya que nos fijaremos más en los posibles efectos colaterales que en otro problema no relacionado que tenemos delante. Es otro motivo para tener una estrategia de migración inversa que devuelva el sistema a su estado inicial.
Y, una vez que tenemos la estrategia inversa, también es importante (y de nuevo contraintuitivo) que lo mejor es no realizar la migración inversa, sino buscar las causas profundas de los problemas.
Versión de sólo lectura
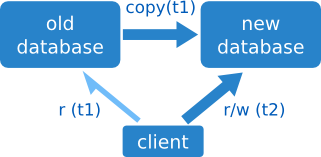
Ahora veremos una estrategia ligeramente más sofisticada. Los pasos son:
- pasar a modo de sólo lectura,
- hacer una copia en caliente (mientras el sistema está andando),
- cambiar a la nueva base de datos,
- y volver al modo de lectura/escritura.
Mientras el sistema está en sólo lectura se puede acceder a los datos pero no modificarlos. De esta forma nos aseguramos de que se pueda hacer la copia en caliente: como los datos no cambian, no tenemos que preocuparnos de que la copia esté desfasada al terminar.
Esto suele ser bastante mejor que una parada completa. Pero no siempre es posible: ciertos sistemas tienen que estar recogiendo datos nuevos constantemente, así que dejarlos en sólo lectura es como tirarlos abajo.
Otro factor a tener en cuenta es que una copia en caliente puede tardar bastante más que en frío, debido a los accesos constantes.
Reversible: no
La migración inversa es fácil, en teoría: pasar de nuevo a sólo lectura, copiar los datos en sentido contrario y volver a usar la base de datos original. Sin embargo, la copia inversa requiere trabajo extra, incluso si la nueva base de datos es idéntica a la antigua: habrá que invertir el script de copia adaptando las direcciones de las máquinas. Y no hablemos ya si hay que hacer cualquier tipo de conversión de formato.
Siempre podemos preparar la copia inversa como parte de la preparación para la migración; de esta forma estamos preparados para la migración inversa. Pero seguimos teniendo downtime, aunque sea sólo para las escrituras. De ahí que una migración de este tipo no sea realmente reversible.
Caso práctico: Migraciones WordPress
Esta técnica es muy básica: se aplica por ejemplo a las migraciones de WordPress, para no tener que preocuparse de cambios mientras se migra.
Sincronización
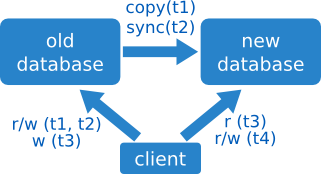
Supongamos de nuevo que tenemos dos bases de datos, la antigua y la nueva. Queremos que ambas queden sincronizadas, de forma que podamos usar una u otra. Los pasos para hacer esta sincronización son:
- hacer una copia en caliente de la antigua a la nueva,
- sincronizar todas las escrituras de la antigua a la nueva,
- pasar a leer de la nueva (pero seguir escribiendo en la antigua),
- y finalmente pasar a escribir a la nueva.
La sincronización se hace en este caso mediante un mecanismo de servidor, que recoge todas las escrituras y pasarlas a otro sistema. No siempre es posible hacerlo: a veces la carga en el sistema antiguo es demasiado grande, o puede que no haya forma de fechar los cambios para extraer sólo los últimos, lo que haría la sincronización total demasiado costosa.
Reversible: sí
En el lado positivo, los usuarios no notarán ningún downtime al acceder al sistema.
Además, la estrategia inversa es trivial: sólo hay que volver a cambiar los accesos a la base de datos antigua, mientras sigamos escribiendo en ella y no desconectemos el mecanismo de sincronización.
Pero si ya no estamos sincronizando los cambios o hemos pasado a escribir en la nueva, la cosa cambia: la migración inversa requiere entonces sincronizar los datos en el sentido contrario. La sincronización bidireccional a menudo es demasiado costosa como para ser práctica. Así que hay que tener cuidado de seguir sincronizando hasta que estemos seguros de que la migración ha sido exitosa y no vamos a querer revertirla nunca.
Caso práctico: Estadísticas diarias en MediaSmart Mobile
En MediaSmart Mobile almacenamos datos de estadísticas del día, conocidos internamente como daystats, para su consulta posterior por usuarios y clientes. Guardarlos todos en Redis nos estaba causando costes ingentes, así que decidimos migrarlos a Redshift para su consulta offline.
Esta base de datos para data warehousing tiene muchas cosas buenas, pero no permite carga en tiempo real. El proceso de carga en Redshift suele ejecutarse cada día o cada hora; en nuestro caso decidimos exportar días completos, por lo que los últimos datos tienen que consultarse siempre en Redis. El desarrollo no fue trivial: según las fechas pedidas hay que acceder a Redis para los datos de los últimos días, acceder a Redshift (que tiene un modelo de datos completamente distinto basado en SQL) para el resto, acumular ambos juegos de valores y presentarlos al usuario.
La parte positiva es que la migración fue completamente suave. En este caso, la sincronización se mantiene siempre (disfrazada de carga de datos), por lo que para dejar de usar la nueva base de datos en Redshift sólo tenemos que cambiar un parámetro de configuración. Así que cuando se reportaron bugs fue trivial comparar ambos, y volver a la versión anterior mientras se investigaba por qué no funcionaban bien datos migrados.
Copia doble
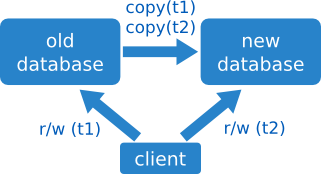
En este caso queremos copiar los datos en dos tandas, una antes de cambiar el acceso y otra después. Los pasos a seguir son los siguientes:
- realizar una copia en caliente mientras se accede al sistema antiguo,
- empezar a leer y escribir en el sistema nuevo,
- y realizar una segunda copia en caliente del sistema viejo al nuevo.
Es importante señalar que con esta estrategia estamos durante un tiempo accediendo a una versión antigua de los datos: cuando empezamos a usar el sistema nuevo todavía no se han copiado todos los datos que han llegado mientras se hacía la primera copia.
Además, la segunda copia requiere de algoritmos algo más sofisticados que la primera: si un mismo registro ha sido modificado durante la primera copia en el sistema antiguo, y luego durante la segunda copia en el sistema nuevo, hay que saber mezclar los datos. Para hacerlo con garantías tenemos que trabajar siempre con modificaciones atómicas, lo que puede resultar bastante incómodo y llevar a conflictos. En esencia es como una mezcla (merge) de código de dos ramas: ¿cómo resolvemos los conflictos sin intervención humana?
Otra opción es ignorar una de las dos actualizaciones y quedarse, digamos, con la última edición de los datos. O directamente sobrescribir con la versión que estamos copiando.
Esta estrategia no es siempre factible: no siempre tenemos el lujo de poder prescindir de los últimos datos, aunque sea durante un tiempo; ni de poder ignorar las actualizaciones que lleguen en un momento poco oportuno. Lógicamente no es buena estrategia para datos financieros, por ejemplo.
Reversible: realmente no
En principio este tipo de migración no tiene downtime asociado, lo que podría hacernos pensar que es reversible. Pero la migración inversa requiere de esfuerzo extra: es necesario hacer una copia en sentido inverso para recuperar los últimos cambios. O eso, o perder todos los datos que han llegado al sistema nuevo.
En general, la ausencia de downtime es condición necesaria, pero no suficiente, para la reversibilidad. El único criterio realmente fiable es estudiar la migración inversa.
Caso práctico: Perfiles en MediaSmart Mobile
En nuestra empresa guardamos perfiles anonimizados de usuarios, con información sobre qué categorías de contenido han visitado. Los perfiles nos ayudan a centrar el targeting y conseguir mejores respuestas.
Cuando teníamos unos 500 millones de perfiles toda la información estaba guardada en Redis, que necesita tener todos los datos en memoria. Así que en cierto momento decidimos moverlo todo a DynamoDB, que también responde muy rápido y tiene capacidad ilimitada. Cuando llegó el momento de la migración nos dimos cuenta de que copiar los perfiles llevaba más de un día. Pero contábamos con la ventaja de que en realidad no pasa nada si se pierden unos cuantos perfiles… o unos cuantos millones. Tampoco pasa nada si un perfil no se actualiza con los últimos cambios, sigue siendo valioso.
Así que nos decidimos por una copia doble. Primero copiamos los perfiles a DynamoDB, tarea que nos llevó dos días, y empezamos a usar esta nueva base de datos desde un solo servidor de prueba. Cuando estábamos contentos con el resultado cambiamos el resto de servidores. En este punto volvimos a hacer una copia de los perfiles para recoger los cambios que habían entrado durante las pruebas. Cuando había dos versiones del mismo perfil, podíamos elegir si quedarnos con la de Redis o la de DynamoDB; realmente sólo perderíamos una pequeña cantidad de información.
La migración fue realmente suave. La vuelta atrás trivial habría conllevado usar la base de datos antigua, lo que podría haber supuesto perder información de días o semanas; por suerte no tuvimos que usarla. A día de hoy tenemos más de mil millones de perfiles, y creciendo.
Catálogo de estrategias en cliente
Como ya hemos visto, en una migración conviene separar acceso y datos. Ahora vamos a ver algunas estrategias que modifican el acceso a los datos, modificando el cliente en lugar del servidor.
Hemos elegido estrategias en cliente que sean reversibles, aunque es necesario que la estrategia del servidor sea también reversible.
Adaptador
Esta estrategia de cliente es la que nos permite cambiar rápidamente de una base de datos a otra, cuando son diferentes. Podemos “disfrazar” una base de datos para que aparente ser otra usando el patrón clásico de adaptador, y luego configurar a qué base de datos accedemos.
Código de ejemplo
El driver de Memcached es muy sencillo, tiene dos funciones básicas:
Para hacer un adaptador para Redis, simulamos la interfaz de Memcached:
var redis = require('redis');
exports.RedisAdapter = function(port, host) {
// self-reference
var self = this;
// attributes
var client = redis.createClient(port, host);
self.get = function(key, callback) {
client.get(key, function(error, result) {
if (error) return callback('Could not get ' + key + ':' + error);
return callback(null, JSON.parse(result));
});
self.set = function(key, value, callback) {
return client.set(key, JSON.stringify(value), callback);
});
};Para crear el driver sólo tenemos que fijarnos en si se trata de una
dirección que empiece por redis: o de una dirección
tradicional:
var MemcachedAdapter = require('./memcached.js').MemcachedAdapter;
var RedisAdapter = require('./redis.js').RedisAdapter;
var settings = require('./settings.js');
var db = {
main: getAdapter(settings.MAIN_DB_ADDRESS),
};
function getAdapter(address) {
if (address.indexOf('redis:') === 0) {
var redisAddress = address.substringFrom(':');
var host = redisAddress.substringUpTo(':');
var port = redisAddress.substringFrom(':');
return new RedisAdapter(host, port);
} else {
return new MemcachedAdapter(address);
}
}Y luego al usar el driver no tenemos que preocuparnos de si estamos hablando con Redis o con Memcached:
db.main.get('hi', function(error, result) {
if (error) return console.error('Got error: %s', error);
console.log('Got result %j', result);
};Caso práctico: Memcached en MediaSmart Mobile
En MediaSmart empezamos usando Couchbase, una base de datos clave-valor enriquecida con una historia curiosa.
La base de datos Memcached original se creó en 2003 por Brad Fitzpatrick para LiveJournal. Era básicamente una capa de cacheo: una base de datos clave-valor que guarda todo en memoria. Membase se creó como una base de datos con una interfaz 100% compatible, pero capaz de guardar los datos en disco. Más tarde CouchDB y Membase se unieron para crear Couchbase, manteniendo la interfaz de Membase, compatible a su vez con Memcached.
Durante un tiempo Couchbase aguantó bien, aunque requería demasiado mantenimiento y el rendimiento se fue degradando. Cuando los tiempos de respuesta empezaron a ser alarmantes, nos planteamos pasar a Redis: otra base de datos clave-valor con persistencia a disco. El problema es que el driver era algo diferente: para empezar necesitaba recibir siempre texto en lugar de admitir objetos y convertirlos a JSON él mismo.
Tras crear el adaptador, era cosa sencilla elegir si usábamos Memcached o Redis para cada instancia de base de datos.
Consulta dual
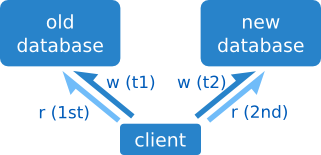
Esta técnica es muy sencilla: empezamos a escribir en la nueva base de datos, y a la hora de leer leemos de ambas: primero miramos en la nueva, y si no está, tiramos de la antigua.
La migración de datos en el servidor se puede hacer con una sencilla copia en caliente.
El problema más obvio es que el tiempo de lectura se duplica, cosa que no siempre es aceptable.
También puede ser un problema si las claves se pueden borrar: con
esta estrategia estaremos dando por bueno un valor de la base de datos
antigua que ya no existe en la nueva. En este caso es recomendable usar
otra estrategia, aunque también se puede usar un valor null
que indique que la clave está vacía.
Código de ejemplo
La clase de acceso es tan sencilla como esto:
exports.db = {
v1: new RedisAdapter(settings.oldRedis),
v2: new RedisAdapter(settings.newRedis),
};y el cliente sólo tiene que hacer:
function get(key, callback) {
db.v2.get(key, function(error, result) {
if (error || result) callback(error, result);
db.v1.get(key, callback);
});
}Escritura dual
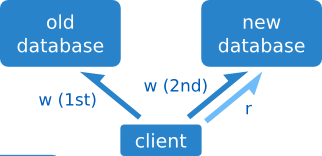
Esta técnica es similar a la anterior, pero en lugar de leer de dos sitios, escribimos a dos sitios.
La escritura dual sirve para mantener dos servidores sincronizados después de haber pasado de usar uno al otro.
En este caso la latencia añadida puede no ser un problema, siempre que las escrituras se realicen de forma asíncrona tras terminar de procesar las peticiones. En el caso de que requiramos confirmación de escritura en ambas bases de datos la latencia aumentará.
Caso práctico: Backup en ING
Por requerimientos del Banco de España, un banco debe almacenar sus datos al menos en dos centros de datos separadas por suficiente distancia. En el banco ING se mantienen dos centros de datos en dos ciudades distintas: uno primario y otro secundario, ambos con la capacidad suficiente como para dar servicio a todos los clientes. En caso de catástrofe se pasa a usar el secundario.
Hace unos años se pasó de tener una réplica en caliente a una réplica online: todas las escrituras debían confirmarse en ambos centros antes de darse por finalizadas. De esta forma se tiene la garantía de que los datos son iguales en ambos centros, y se puede pasar de uno a otro a voluntad.
Paso temporizado
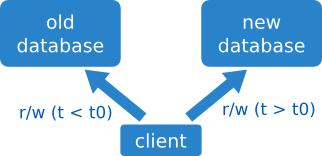
En este caso el cliente usará un servidor u otro dependiendo de los datos a acceder, con una fecha de corte configurable.
El resultado es un cambio suave de servidores, a costa de añadir como mucho unos pocos microsegundos (µs) a cada query.
Código de ejemplo
Un objeto se usa para recubrir dos alternativas, y se selecciona la adecuada según la fecha actual.
var Memcached = require('memcached');
exports.CleverAdapter = function(name, address) {
// self-reference
var self = this;
// attributes
var oldAdapter = new Memcached(address + ':11211');
var newAdapter = new RedisAdapter(address);
self.get = function(key, callback) {
if (new Date().toISOString() < '2015-11-14') {
return oldAdapter.get(key, callback);
}
return newAdapter.get(key, callback);
}
};Caso práctico: Agregados en MediaSmart Mobile
De nuevo usaremos las estadísticas diarias (daystats) que se pueden consultar en el pasado.
En cierto momento las consultas empezaron a ir demasiado lentas, así que añadimos agregados que se actualizan automáticamente y que nos evitan leer muchas claves a la vez para conseguir un solo resultado. A partir de cierto momento empezamos a guardar estos agregados. Pero nos queríamos ahorrar hacer un proceso batch que se recorriera todos los días anteriores y calculara los agregados, así que simplemente pusimos como fecha de corte el día posterior a activar los agregados: si la consulta era posterior a este día se usarían los agregados, y si no, haríamos la consulta habitual.
Sencillo y elegante, y que nos ahorró un montón de trabajo.
Conversión in situ
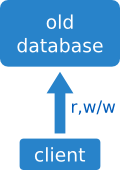
Queremos cambiar el formato de los valores de un cierto tipo. En lugar de recorrer todos los valores existentes y modificarlos, podemos empezar a escribir los valores nuevos con este nuevo formato, e ir modificando los antiguos según se leen.
La lectura de cualquier valor consta de los siguientes pasos:
- Leer el valor.
- Si tiene el formato nuevo, devolverlo tal cual.
- Si tiene el formato antiguo, convertirlo al nuevo formato y guardarlo de nuevo.
- Devolver el valor resultante de la conversión.
La migración de formato se va haciendo poco a poco según se van leyendo valores. En un momento dado podemos hacer un repaso a todos los registros restantes, leyéndolos y convirtiéndolos en su sitio. En cualquier caso nos hemos evitado hacer la migración de formatos de un golpe.
En esta conversión no hay sistema antiguo y nuevo: sólo hay un sistema. Es un caso “degenerado” de las migraciones que hemos visto hasta ahora. También es especial porque no hay parte de servidor: toda la migración se hace en el cliente.
Esta migración es adecuada para cambios internos en la estructura de cada registro, no para modificaciones de estructura en bases de datos SQL que sí tienen que hacerse de un golpe.
Código de ejemplo
El cliente lee un registro en el que la fecha puede estar en formato numérico o como cadena en formato ISO. Lo queremos siempre como cadena, así que si es un número lo convertimos a cadena y lo volvemos a guardar. En cualquier caso se lo pasamos a la callback con el formato de cadena esperado.
function getValue(key, callback)
{
db.get(key, function(error, value)
{
if (error) return callback(error);
if (typeof value.timestamp == 'number')
{
value.timestamp = new Date(value.timestamp).toISOString();
db.set(key, value, function(error)
{
if (error) log.error('Could not store value: %s', error);
});
}
return callback(null, value);
});
}Caso práctico: Compresión de perfiles en MediaSmart Mobile
Volvemos a encontrarnos con los perfiles de MediaSmart Mobile. En cierto momento encontramos que teníamos ya más de 100 millones de perfiles, y que ocupaban demasiado espacio. (Era antes de la migración a DynamoDB, y en Redis se almacena todo en memoria.) Así que decidimos comprimir los perfiles más habituales para reducir el espacio usado.
Cada perfil consta de una serie de valores que tienden a repetirse, como el rango de edades o las categorías visitadas previamente. Para comprimir los perfiles decidimos tomar los valores más comunes y codificarlos con un formato especial que nos permitiera reconocer que se trataba de un valor codificado. El perfil resultante ocupaba bastante menos que el original, pero una vez más queríamos evitar una migración a gran escala.
Así que decidimos hacer una conversión in situ: al leer los perfiles teníamos que descomprimirlos en cualquier caso, así que aprovechamos la circunstancia para ir guardándolos comprimidos según se iban leyendo y modificando. En el proceso nos ahorramos varios cientos de GB de datos.
Catálogo de estrategias en broker
A continuación vamos a ver un par de estrategias que dependen de una máquina intermedia entre el cliente y el servidor, a la que vamos a llamar “broker”.
De nuevo estas estrategias suelen requerir una migración en el servidor paralela, así que tampoco investigaremos si son reversibles o no. Dado que son similares a las estrategias en cliente tampoco veremos casos prácticos; sólo las mencionamos de pasada.
Acceso mediante proxy
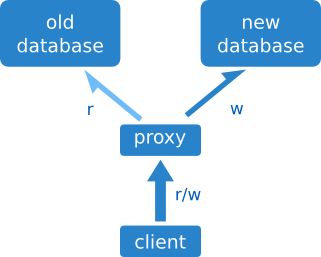
El broker es en este caso un proxy, que envía las consultas a un servidor o a otro según un valor de configuración. El cliente no tiene que preocuparse de enviar las consultas al servidor correcto; el broker se ocupa de todo.
El problema más evidente es que añadimos tiempo a la consulta, y además un nuevo punto de fallo.
Código de ejemplo
El proxy tiene a la vez un servidor y un cliente.
const http = require('http');
const request = require('basic-request');
http.createServer((request, response) => {
const url = 'http://newserver.com' + req.path;
request.get(url, function(error, body)
{
if (error)
{
response.writeHead(500);
response.end('Could not reach
return;
}
response.writeHead(200, { 'Content-Type': 'text/plain' });
response.end(body);
});
}).listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});Escritura en cola
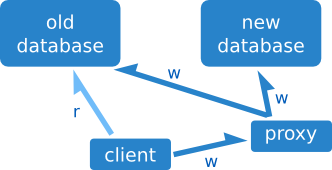
En este caso no escribimos directamente en destino, sino que almacenamos las escrituras y las hacemos todas de golpe.
Es muy común en los servidores de base de datos (por ejemplo Couchbase) agrupar las escrituras para ahorrar procesamiento. En nuestro caso podemos enviar las escrituras al servidor que convenga para nuestra migración.
Migración de cualquier tipo
Todas las estrategias que hemos visto son útiles no sólo para migraciones de base de datos. En lugar de copiar datos es posible que tengamos que copiar configuraciones, código o ficheros planos. En cualquier caso tendremos que ocuparnos de dos cosas: migrar los accesos, y mover la información necesaria. Cada parte puede resolverse de forma separada, lo que nos da dos grados de libertad que nos pueden ayudar en nuestro trabajo.
En cualquier migración querremos evitar tener downtime, no sólo por no molestar a nuestros clientes: por orgullo, y porque dejar de dar servicio es mala ingeniería.
Caso práctico: Migración de Instagram a Facebook
Tras la compra de Instagram, Facebook tenía lógicamente interés en que se usaran sus centros de datos. Instagram se embarcó en una migración de dimensiones épicas, y tuvo a bien documentarla en su blog de ingeniería. Se trataba de migrar miles de instancias, y como buenos ingenieros se plantearon hacerla sin pérdida de servicio.
El proceso llevó un año completo, de 2013-04 a 2014-04. El primer paso fue migrar a AWS VPC, la red privada virtual de Amazon. Este paso era necesario para evitar colisiones de direcciones IP ya que Facebook usa el mismo espacio privado que AWS.
Así que decidieron crear Neti: un servicio de manipulación de tablas de IPs dinámicas que permitía compatibilizar los accesos a máquinas, sin importar si residen en VPC o en la red clásica. Ésta herramienta permitía configurar cada servidor para funcionar La migración a VPC llevó tres semanas.
A partir de ahí, la migración de VPC a Facebook llevó otras dos semanas adicionales. Las herramientas de gestión de Instagram (provisionamiento de servidores) se ampliaron para funcionar tanto en AWS como en el entorno de Facebook.
Todo esto para un esfuerzo planteado como migración mínima.
Sigue fluyendo
Hay otros aspectos de las migraciones que considerar antes de despedirnos.
Minimizando los errores
El aspecto que más miedo da de cualquier migración es probablemente tener un error grave: en estas circunstancias es fácil dejar de dar servicio o incluso perder gran cantidad de datos.
El equilibrio inestable
Un sistema que fluye se mantiene en equilibrio, pero no es necesariamente un equilibrio estable.
Caso práctico: Punto neutro
Veamos un ejemplo sacado de una ingeniería completamente diferente a la nuestra: la aerodinámica. Los aviones supersónicos tienen que funcionar en dos regímenes completamente diferentes: primero tienen que volar en modo subsónico, y una vez que alcanzan la velocidad del sonido pasan al modo supersónico. Esto causa un problema: el centro de gravedad está por detrás del punto neutro, lo que hace que el vuelo sea inestable. La única forma de mantenerlos en el aire sin que se desintegren es corregir la trayectoria con un ordenador de a bordo, sin el cual el vuelo sería completamente imposible.
(Los aviones acrobáticos también son inherentemente inestables, lo que los hace más manejables, pero al volar a menos velocidad es posible que un piloto los controle.)
Velocidad de crucero
Un sistema que fluye demasiado despacio se vuelve también difícil de manejar, lo que podemos contrarrestar aumentando la velocidad del cambio. Pero en este caso el sistema se vuelve inestable, y hay que controlarlo para que los fallos que van surgiendo no se acumulen.
La velocidad de crucero óptima es la que nos permite realizar cambios al sistema de la forma más rápida, sin comprometer la integridad del sistema.
Seguridad por defecto
La mejor forma de intentar evitar errores es tener secure defaults: que la forma de operación por defecto sea segura.
La monitorización activa es la primera línea de defensa: un sistema que envíe notificaciones a los administradores. Pero no podemos quedarnos ahí. El ejemplo más típico es el dispositivo de hombre muerto: un mecanismo que detiene el tren si el maquinista no lo pisa cada cierto tiempo.
Otro ejemplo clásico es el canario que se introducía en la mina de carbón para que avisara de cualquier fuga de gases venenosos. En nuestro caso, lo ideal es conectar el canario con el dispositivo de hombre muerto para que nuestro sistema vuelva a la operación segura por sí solo ante cualquier problema.
Caso práctico: Parada de bidding en MediaSmart
En MediaSmart hemos tenido unos cuantos problemas serios con el sistema de bidding automático que nos han causado pérdidas monetarias. En una startup española el dinero no suele sobrar, así que siempre que nos hemos encontrado con problemas serios hemos buscado formas de operación seguras.
Actualmente, aparte de múltiples notificaciones de condiciones anómalas, hemos optado por parar el bidding preventivamente antes que perder dinero. Varios de nuestros “canarios” son capaces de parar el bidding de forma autónoma para que el sistema no siga pujando, ante cualquier síntoma de alarma. La vuelta a la normalidad se hace también de forma automática, salvo en casos extremos que requieran de revisión manual.
Vivir con errores
Cuando estamos haciendo tareas delicadas es inevitable que, más tarde o más temprano, cometamos un error. Todas nuestras medidas de seguridad sólo nos ayudan a evitar problemas pasados, pero es difícil precaverse de todos los problemas futuros. La única forma de no meter la pata es no hacer nada, nunca. Si decidimos seguir este camino nos quedaremos con una arquitectura rígida y difícil de cambiar.
Por suerte, la forma más segura de operar es además la que más nos conviene: una migración reversible, donde sea tan fácil ir hacia atrás como hacia adelante. El precio a pagar es que, de vez en cuando, cometeremos errores. Hay que aceptarlo y seguir hacia adelante.
Entre tanta migración, no hay que perder de vista el objetivo final: tener una arquitectura flexible y que pueda adaptarse a las nuevas circunstancias rápidamente. En el entorno moderno una arquitectura que no es capaz de amoldarse a las nuevas circunstancias está obsoleta desde antes de probar su valía en producción.